NeXus: adding semantics¶
Remaining issues¶
HDF5 solves most of the technical issues raised by storing detector images into individual files. However, a class of problems remain affecting in particular automatic data analysis or long time archiving of the data. The major reason for this is that HDF5 is totally agnostic about what the data, stored within an HDF5 file, represents in the real world.
From this point of view the situation with plain HDF5 is rather similar to that the IUCR faced with the STAR file format. Though, the STAR format is capable of storing all kind of data (as ASCII) in a structured manner, it had no standardized way to add context to the data. This lead ultimately to the development of CIF and related formats which are a subset of the STAR file format.
To get a better idea for this class of problems lets consider a simple example. Imagine a very simple synchrotron experiment where data is recorded from the following sources
- the storage ring
- the undulator
- the monochromator
- a monitor detector
- a sample stage
- a 2D detector.
In the traditional approach every data item collected during the experiment would get a unique name and stored below this name in a column of a table. The major problem with this is that we have to know that, for instance, x_s and y_s are the x and y translations of the sample stage, or that r_curr is the actual current in the storage ring. Besides this, data stored in ASCII files has typically no units physical associated with it. Thus we have to know in advance that mr_1, let’s say the roll of the first mirror, is recorded in milli-radiants and not in degree. Putting it all together, some of the problems we had with plain ASCII files remain for HDF5. These would be
- we have to know the context of a particular data item in advance
- there is no physical unit associated with numeric data
- every attempt to add context to the name of an item will quickly lead to rather unhandy long names.
Adding semantics¶
This is the point where NeXus enters the stage. NeXus is not a new physical file format. It is rather a set ofrules and conventions how to organize data within an HDF5 file.
Attention
This is a rather common missconecption: NeXus files are HDF5 files. Every software that can read HDF5 files can also read NeXus files. The NeXus standard does nothing else than determining the structure of the file up to a certain point.
Adding units to a particular dataset (in NeXus terminology they are called fields) is rather simple. The NeXus standard requires that every dataaset has a string attribute with name units attached to it, storing the string representation of the physical unit of the data stored in the field (dataset).
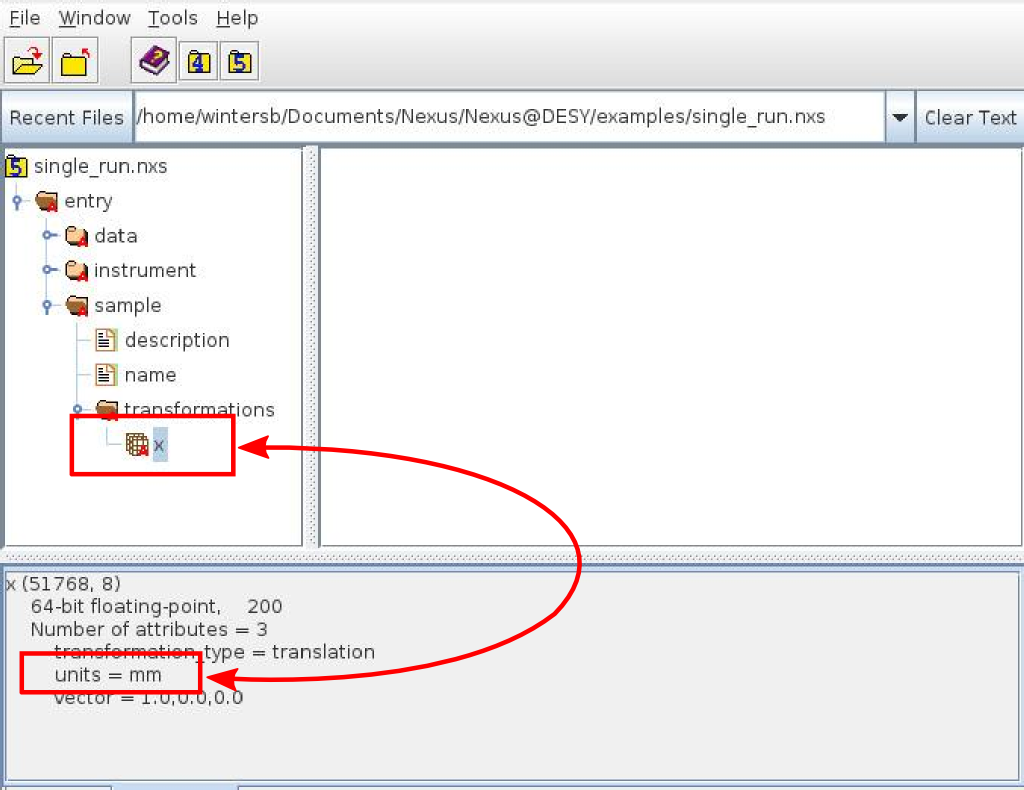
The physical unit of a field is determined by the value of the units attribute attached to it.
The string in the units attribute should follow the UDUNITS library standard.
The second job, associating every dataset with a particular object at the beamline is a bit more complicated. The NeXus way of doing this is by adding types to every group and by storing fields belonging to a particular object within such a group. For instance a group storing data of detectors is of type NXdetector. The type of a group is encoded in a string attribute of name NX_class attached to the group.
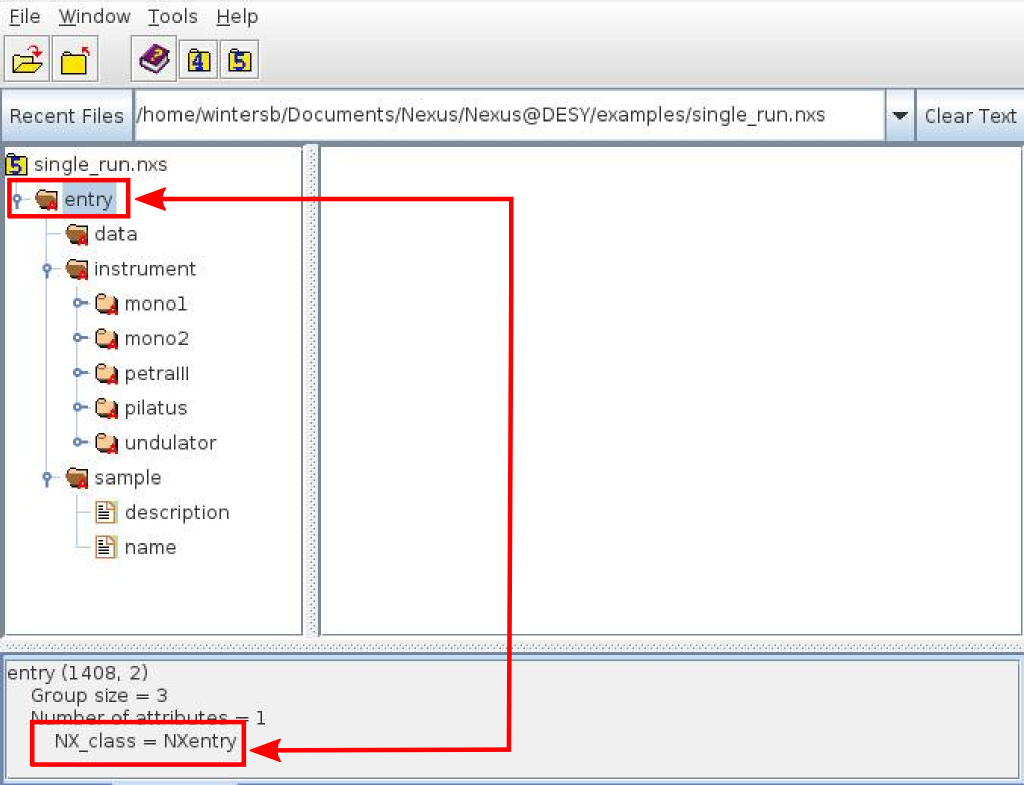
The type of a group is determined by the value of its NX_class attribute. In this case the top level group with name entry is of type NXentry. See blow for what this means.
These types are called base classes in NeXus terminology. But they do much more than associating a dataset (field) with a particular object. Every base class also defines a set of datasets and theirs names which can appear within a group of this type and determines its particular meaning. The base classes are defined in the base class section of the NeXus reference manual. NXdetector for instance has a field named data which is supposed to store the data recorded from this particular detector. It also defines to fields name x_pixel_size and y_pixel_size storing the size of each pixel of this very detector. In this way, base classes not only help associating data with a particular device at the beamline, they also add meaning to the data stored within each class. Finally, whenever we arrive at a group of a particular class we can make educated guesses what fields we can find there. This greatly helps when writing automatic analysis software which should identify the required data by itself without user interaction.
The basic structure¶
Aside from concrete devices like detectors, attenuators and the storage ring, the NeXus standard also defines base classes of rather abstract nature. There primary purpose is to define the basic structure of an experiment run within a file. The most important of these base classes are
| base class | description |
|---|---|
| NXentry | the top level group of every experiment. It is the entry point for the data tree of a single experiment run. |
| NXinstrument | located below NXentry, storing every component of the beamline except the sample and all data associated with it. |
| NXsample | like NXinstrument, NXsample resides below NXentry. It contains every data associated with the sample (including for instance the position of every stage the sample is mounted on. |
| NXdata | below NXentry collecting data from this particular run used for plotting. |
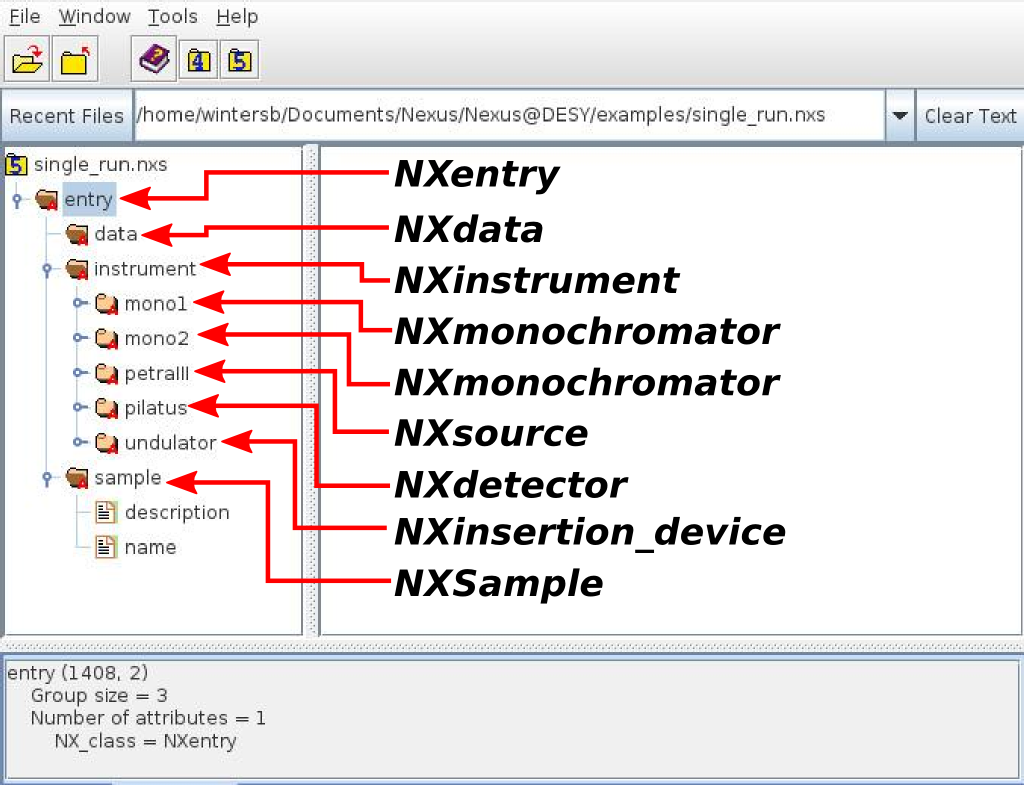
A typical default NeXus tree shown in HDFview. An instance of NXentry acts as the top-level element for a run.
Addressing objects within a NeXus file¶
To address an object within an HDF5 file a Unix like path is used. However, this requires that the names of each group between the target dataset and the root of the tree is known. This would require rather strict naming conventions which are neither practical nor would they make NeXus easy to use. Consequentevery analysis script or program would have to know the exact path to every bit of information required to do its job. The concept of types in NeXus can be used to relieve this constraint in many cases.
Instead of searching for a path we can look for a type. So for instance instead of saying
/entry/instrument/pilatus/data
which would translate to give me the field name data within the group pilatus one could ask
/entry/instrument/:NXdetector/data
which reads: give me the field named data in the first instance of NXdetector you find. This of course would require that the instrument group only holds one instance of NXdetector. If we assume now that the file contains data from only on run, meaning that it has only one entry below the root we can generalize the above path to
/:NXentry/:NXinstrument/:NXdetector/data
in which case the only name we have to know is that of the dataset we want to access. However, this is easy as the name data is standardized by the base class NXdetector. With only two restrictions, namely
- there is only on entry in the file
- only on detector is used
no group names must be known by the user. It is thus possible to write rather generic paths used in generic scripts.